Siguiente: Conclusiones Subir: Implementación de un cluster Anterior: Administración del cluster
Subsecciones
- Pruebas generales de rendimiento del cluster
- POV-Ray / Povmosix
- Programas paralelos con LAM/MPI, ejemplo del cálculo del área bajo la curva de una función
- Ejecución de programas del Instituto de Ingeniería
Desempeño y pruebas de rendimiento
Ya se ha terminado con la implementación de OpenMosix, la instalación de los compiladores con las librerías necesarias y también se han hecho todas las configuraciones necesarias para el correcto funcionamiento. Ahora se muestran los resultados de pruebas realizadas con algunos programas de uso general y particular que se ejecutaron en el cluster.
Pruebas generales de rendimiento del cluster
Para cada una de las pruebas, se describe la herramienta o programa que se utiliza para tener un panorama general de la aplicación, posteriormente se explican los resultados que se han tenido para cada una de ellas.
POV-Ray / Povmosix
POV-Ray (Persistence of Vision Ray Tracer), es un avanzado software gratuito para trazado de rayos, el cual es un método para generar imágenes fotorealistas por computadora y se basa en el algoritmo de determinación de superficies visibles de Arthur Appel denominado Ray Casting.
Para describir los objetos se hace uso de un modelador gráfico o mediante un archivo de texto en el que van descritos los objetos que forman la escena. El resultado es un archivo donde se especifican los objetos, texturas, iluminación y la colocación de la cámara virtual que sacará la foto de la escena.
Povmosix![[*]](footnote.png) es un programa que puede proveer renderizado en paralelo para POV-Ray en un ambiente OpenMosix. Éste divide la escena llamada tarea en un conjunto de ``subtareas'' y éstas pueden migrar en el cluster. Cuando todas las subtareas terminan, la imagen resultante es generada de las salidas parciales.
es un programa que puede proveer renderizado en paralelo para POV-Ray en un ambiente OpenMosix. Éste divide la escena llamada tarea en un conjunto de ``subtareas'' y éstas pueden migrar en el cluster. Cuando todas las subtareas terminan, la imagen resultante es generada de las salidas parciales.
En este trabajo, se hicieron pruebas con el archivo benchmark.pov, el cual es una demostración elaborada de lo que se puede llegar a generar con POV-Ray y está incluido con los archivos de instalación de este mismo software. Como ya se mencionó, en este archivo de texto, se describe a los objetos de la escena. Por ejemplo, con el código que se muestra a continuación, se describe la colocación y el tipo de letra de un texto en la escena:
[fontfamily=courier,fontshape=it,fontsize=\small,baselinestretch=0.8]
#declare POV_Text =
text {ttf
"timrom.ttf"
"OPENMOSIX-II"
0.25,0
scale 0.3
rotate 90*x
rotate -90*z}
![\includegraphics[scale=0.39]{Chapter-7/Figures/povmosix1024x768}](img34.png)
El resultado es una imagen con resolución de 1024x768 píxeles, la cual se muestra en la figura ![[*]](crossref.png)
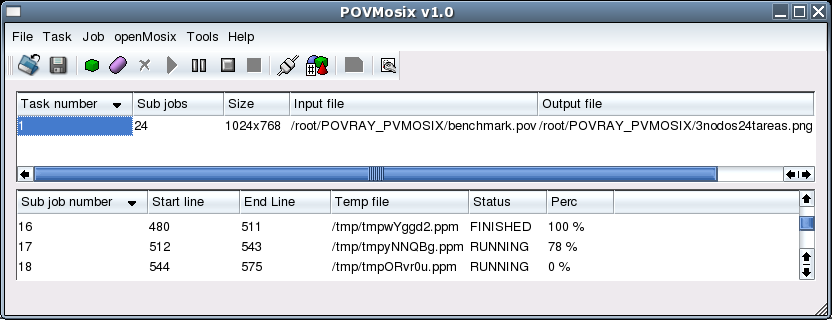
En la figura se muestra la interfaz de ejecución de Povmosix, en ella podemos iniciar y administrar la ejecución de los procesos y subprocesos para la generación de una escena POV-Ray. Con esta herramienta se hizo una serie de ejecuciones con diferente número de nodos y de procesos. Estas se hicieron de acuerdo al cuadro y con los resultados mostrados ahí mismo.
Para una mejor comprensión del cuadro , se muestra la figura . Como puede observarse en ella, en el caso específico de Povmosix, el rendimiento del cluster OpenMosix es mejor cuando el número de tareas es mayor que el número de nodos activos, pero esto sólo hasta cierto límite. Esta particularidad es debida a que cada subtarea generada por Povmosix tiene diferente carga de trabajo y por tanto no tiene el mismo tiempo de ejecución.
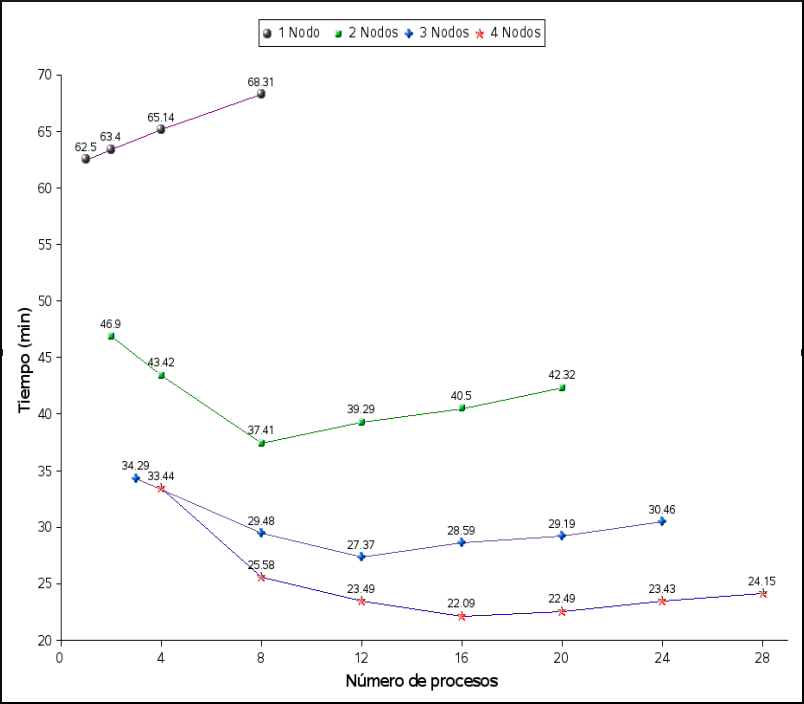
Para la generación de estas imágenes fotorealistas, con la configuración del cluster y con ayuda de Povmosix, podemos tomar ventajas para optimizar tiempos de generación de escenas.
En esta primera aproximación al uso del cluster OpenMosix se observa la utilidad que se puede dar a una herramienta como ésta y se muestra como pueden obtenerse mejores resultados dependiendo del número de tareas que se ejecuten en los nodos disponibles. Otra observación importante que se hace, es que esta mejora en rendimiento al aumentar el número de tareas es debida muy particularmente a la forma en que trabaja Povmosix. Hay que tomar en cuenta que no todos los programas están diseñados de igual manera y por lo tanto no todos pueden tomar las mismas ventajas.
Programas paralelos con LAM/MPI, ejemplo del cálculo del área bajo la curva de una función
Se hicieron también pruebas de rendimiento con un programa paralelo con MPI, el código de este puede leerse en el apéndice A.
El programa consiste en calcular el área bajo la curva definida por el polinomio ![]() .
.![]() .
.![]() .
.![]() .
.![]() .
.![]() con limite inferior en 0.0 y superior en 9.5. Cabe mencionar que este programa no tiene utilidad inmediata en este contexto más que para pruebas del cluster.
con limite inferior en 0.0 y superior en 9.5. Cabe mencionar que este programa no tiene utilidad inmediata en este contexto más que para pruebas del cluster.
Para compilar y ejecutar este programa se utilizan los siguientes comandos:
[fontfamily=courier,fontshape=it,fontsize=\small,baselinestretch=0.3] $lamboot LAM 7.1.1/MPI 2 C++/ROMIO - Indiana University $mpicc mpi_integral2.c -lm -o mpi_integral2.out $mpirun -np 4 mpi_integral2.out Integrando la función Y = 10.5 + 1.2x + 0.8x^2 - 2.25x^3 + 0.5x^4 en 150000000 intervalos... Limite Inferior: 0.000000 Limite Superior: 9.500000 proc 1 computes: 884.686245 proc 2 computes: 884.686281 proc 0 computes: 884.686210 proc 3 computes: 884.686316 The integral is 3538.745052
En este caso, el número 4 es el número de subprocesos que generará el programa.
En el cuadro se muestran los resultados de los tiempos resultantes de las pruebas que se hicieron en el cluster.
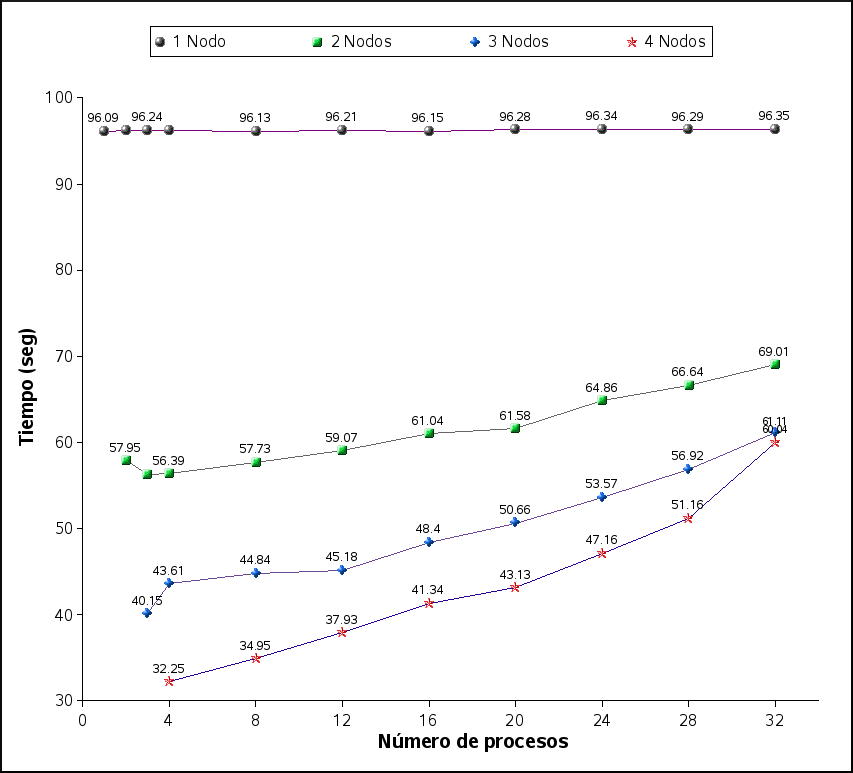
Para mejor comprensión de los resultados, se muestra la figura , con los tiempos obtenidos en las diferentes ejecuciones con uno, dos, tres y cuatro nodos. Como se observa en ella, los mejores tiempos de ejecución se dan cuando el número de subprocesos es igual al número de nodos, lo cual no sucede conforme aumenta el número de procesos en los que se divide la ejecución, en la mayoría de los casos cuando el número de subprocesos es mayor al número de nodos, el tiempo aumenta. Lo cual implica que este programa no es un buen candidato para dividirse en muchas tareas, pero sí para ejecutarse en muchos nodos.
También es importante mencionar que si el número de procesos es menor al número de nodos, se estaría desaprovechando al resto de los nodos.
Ejecución de programas del Instituto de Ingeniería
En esta sección se describe el funcionamiento de los programas utilizados en las coordinaciones en las cuales se ha colaborado y se hizo la implementación del cluster.
Coordinación de Ingeniería Sismológica
Debido a la necesidad de considerar los efectos destructivos que pudieran tener eventos sísmicos como los de 1985, en la Coordinación de Ingeniería Sismológica se procesa un modelo de la corteza terrestre mexicana con influencia de sismos generados en diferentes epicentros y su influencia sobre la Ciudad de México. Esto para ayudar a tomar medidas de prevención, analizando las zonas que pudieran sufrir los daños más severos.
El programa utilizado en esta etapa de pruebas de rendimiento, fue desarrollado por el M. en C. Hugo Cruz Jiménez. En este trabajo se aplicó el método pseudo-espectral para la obtención del campo de onda incidente en la Ciudad de México; el campo de ondas se expande en el espacio en términos de polinomios de Fourier, y las derivadas parciales espaciales se calculan en el dominio del número de onda. En este estudio se consideró conveniente simular el movimiento en 2D para evaluar los efectos de la estructura de la corteza heterogénea y el manto superior de México[HCruz04].
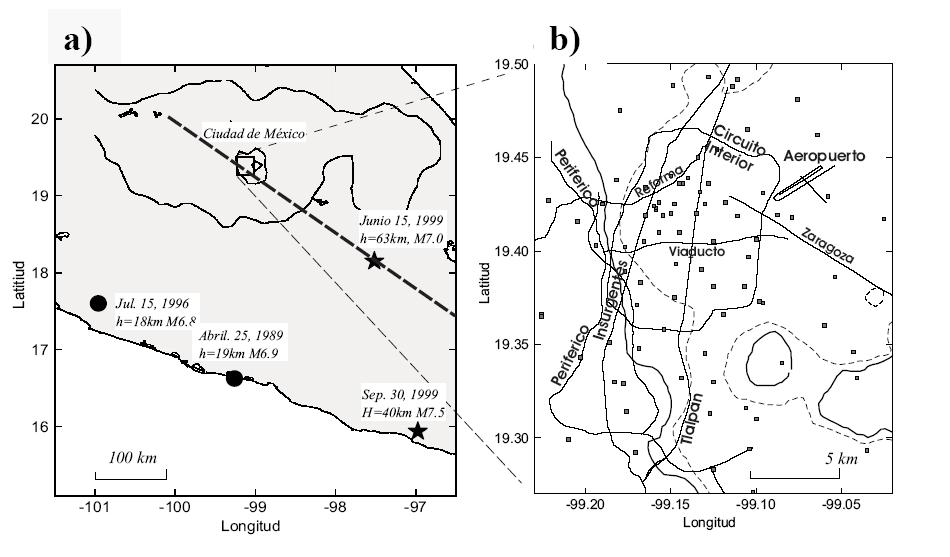
En la figura a, se muestra la localización de los sismos considerados. Los círculos negros y las estrellas muestran los epicentros y la Ciudad de México, y en la figura b, se muestran las localizaciones de las estaciones de movimiento fuerte (cuadros) y algunas avenidas importantes en la Ciudad de México.
La zona modelada tiene 512 Km. de largo por 128 Km. de profundidad. Se utilizó un espaciamiento uniforme de la malla de 0.125 Km., para minimizar las reflexiones artificiales de los bordes del modelo y se utilizó una zona absorbente con 20 puntos de la malla.
En la figura
![\includegraphics[scale=0.5]{Chapter-7/Figures/instantanea1}](img41.png) , se muestran cuatro instantáneas obtenidas a partir del modelado numérico en
dos dimensiones.
, se muestran cuatro instantáneas obtenidas a partir del modelado numérico en
dos dimensiones.
Este programa se ejecuto para ![]() y
y ![]() iteraciones, con las cuales las salidas arrojadas permiten al investigador tener diferentes resoluciones para observar sus resultados.
iteraciones, con las cuales las salidas arrojadas permiten al investigador tener diferentes resoluciones para observar sus resultados.
Los tiempos observados con las ejecuciones de este programa y cálculos promedio se pueden ver en el cuadro
, y para una mejor comprensión de éste, se muestra la figura , con los tiempos obtenidos en las diferentes ejecuciones. Como puede observarse en ésta figura, los tiempos al ejecutar el proceso mejoran conforme se ejecuta en más procesadores y no al ejecutarse con un mayor número de procesos. Lo que implica que solo se ejecuta en un procesador a la vez y la única ventaja es la de poder ejecutar este programa con diferentes datos al mismo tiempo.
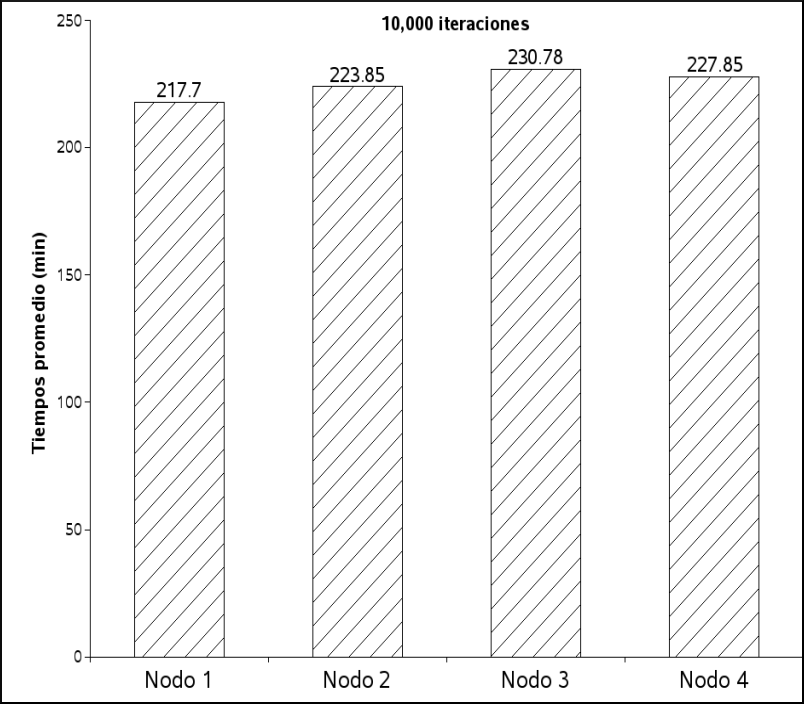
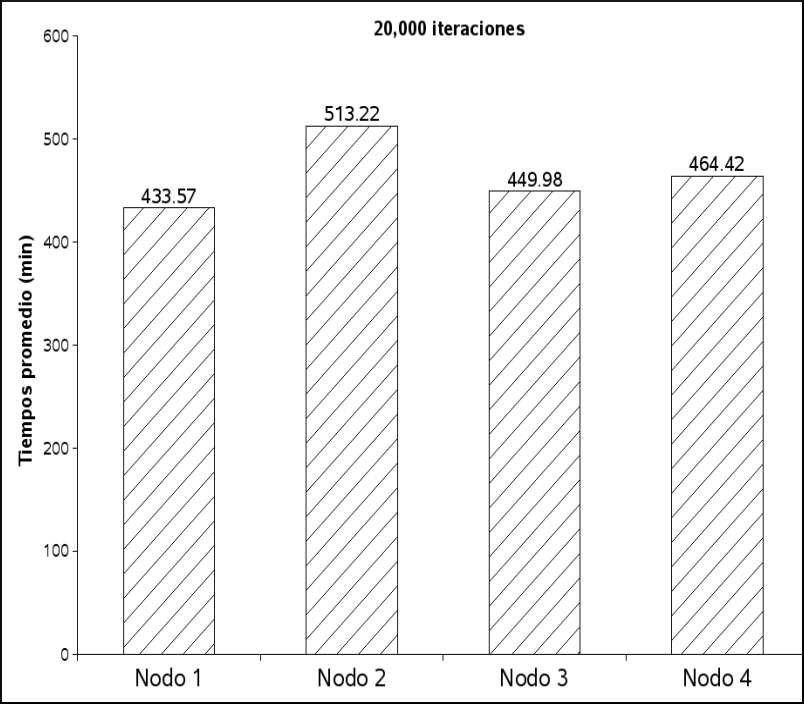
Los tiempos observados con las ejecuciones de este programa y calculando promedios se pueden observar en el cuadro
, y para una mejor comprensión, se muestra la figura , con los tiempos obtenidos de las diferentes ejecuciones. Como se observa en la figura, los tiempos al ejecutar el proceso mejoran conforme se ejecuta en más procesadores y no al ejecutarse con un mayor número de procesos, lo que implica que sólo se ejecuta en un procesador a la vez y la ventaja es la de poder ejecutar este programa con diferentes datos al mismo tiempo.
Coordinación de Mecánica Aplicada
La evolución de la arquitectura de las estructuras a través de los tiempos ha estado subordinada a distintos factores que influyeron para que se desarrollara en un determinado periodo y lugar. Entre ellos se pueden señalar el tecnológico, el cual está ligado al grado de conocimiento y habilidad de los diseñadores y constructores de cada época y que está influenciado de manera importante por la cantidad y calidad del material para cada realización. Es así que la mampostería toma su lugar en la historia de la ingeniería[GRoeder04].
En la Coordinación de Mecánica Aplicada del Instituto de Ingeniería, trabaja un grupo dirigido por el Doctor Gustavo Ayala Milián, aplicando métodos de mecánica numérica. Es el caso del trabajo realizado por el Doctor en Ingeniería Guillermo Martín Roeder Carbo descrito a continuación (ver figura ).
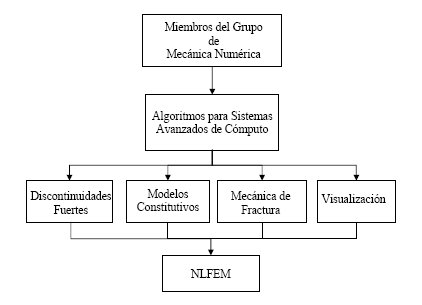
Mediante modelos matemáticos y algoritmos, se han desarrollo e implementado herramientas numéricas para modelación de estructuras de mampostería por el método de elementos finitos, donde con el avance de las nuevas investigaciones se han ido incorporando nuevos procedimientos para la solución de sistemas de ecuaciones no-lineales. La meta de este trabajo fue el desarrollo de una herramienta computacional bajo un sistema robusto para el análisis no-lineal de estructuras de mampostería.
Así, el resultado es NLFEM(Non-Linear Finite Element Models), programa que permite investigar el comportamiento físico y/o mecánico de una gran variedad de sistemas estructurales gracias a la amplia variedad de tipos de elementos incorporados en el que pueden ser aplicados a estructuras de concreto simple y reforzado, asimismo como a estructuras de mampostería. También se puede realizar modelados de problemas de la mecánica de suelos.
Al igual que con el programa de la Coordinación de Ingeniería Sismológica se intentó aprovechar el poder de cómputo que ofrece el cluster OpenMosix. En este caso el resultado final no fue satisfactorio y con el objetivo de entender cuando un programa no puede hacer uso de este tipo de clusters, se hace la siguiente explicación:
NLFEM se comenzó en el año de 1999 y desde entonces ha sido extendido, adaptándose a los requerimientos de las investigaciones. Desde su comienzo, este sistema no fue planeado para poder ejecutarse en un cluster, aunque se sabía, que con el tiempo tendría requerimientos más grandes de cómputo, los cuales serían satisfechos con computadoras monoprocesador o multiprocesador de vanguardia, situación que provoca grandes gastos en la compra de estos recursos.
Por otro lado, la programación del sistema se hizo con tres lenguajes: C, C++ y FORTRAN 77. El programa completo está constituido por otros subprogramas ejecutables escritos en FORTRAN 77 que son llamados entre si mediante el control de procesos padres a procesos hijos, lo cual pone en desventaja el aprovechamiento del cluster, pues como se menciona en la sección 2.4.5 sobre los requerimientos mínimos para la migración de procesos, éstos no deben de hacer uso de la memoria compartida, situación que se genera con la metodología usada en la programación de este sistema.
Otro análisis que se hizo con este sistema, fue sobre la duración en tiempo de ejecución de cada uno de los subprocesos generados por el programa principal, observando que estos tiempos, en el orden de segundos, son muy pequeños y debido al algoritmo de balanceo de carga que utiliza OpenMosix, no es posible que estos migren a otros nodos, pues tardaría más tiempo en trasladarse a otro nodo, que si se ejecutara en el nodo anfitrión.
Siguiente: Conclusiones Subir: Implementación de un cluster Anterior: Administración del cluster
Licencia: Creative Commons

Reconocimiento-NoComercial 2.5 México
JoseCC & SuperBenja, 2006-06-08